World Wide Layoffs (SQL, PBI)
This project involves creating and cleaning a database named world_layoffs to analyze layoff trends. The initial steps focused on building a database structure and importing raw data, followed by a comprehensive cleaning and transformation process.
To begin, I created a database named world_layoffs and added a table named layoffs. The date column was initially set as a VARCHAR because the data was not in the correct format for the DATE type. I plan to clean and convert this column to the appropriate format. Constraints were not applied at this stage due to uncertainty about the data quality. If constraints are necessary, I will clean the data, transfer it to a new table, and implement the constraints at that point.

I used the Table Data Import Wizard to import all the data into the layoffs table, resulting in a total of 2,361 records.


We now begin the data cleaning process, focusing on four key tasks:
removing duplicates
standardizing the data
handling null or blank values
removing unnecessary columns / rows.
General:
I created a new table named layoffs_cleaned to start the data cleaning process.


Removing Duplicates:
Step 1: Identified duplicates by creating a CTE with a window function that partitions by all columns. This allowed me to locate rows with a count greater than 1, indicating duplicates.

Step 2: Created a new table named layoffs_cleaned2 and transferred the data identified in the CTE. Using the row_num column, I removed duplicates from this table, ensuring no duplicate rows remained.


Step 3: Removed duplicates from the new table by filtering rows based on the row_num column.

Standardizing Data:
Step 1. The first step in standardizing the data was trimming unnecessary spaces from the company column.

Step 2. The second step of standardization involved ensuring the industry column did not have fragmented categories. For example, I combined variations like "Crypto," "Crypto Currency," and "CryptoCurrency" into a single category.

Step 3: I found variations of "United States" with and without a period (e.g., "United States" and "United States.").

Step 4: Converted the date_recorded column to the DATE type.

Handling Null and Blank Values
Step 1: For the industry column, I addressed blank and null values by leveraging other records for the same company. First, all blank values were updated to nulls.
Step 2: Next, I performed an inner join with the table itself to match available industry values to the nulls. Using this approach, I populated the missing industry values with corresponding data from other rows.

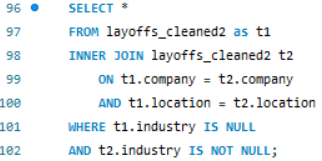

Step 3: For other columns (total_laid_off, percentage_laid_off, date_recorded, stage, country, funds_raised_millions), the missing data could not be filled due to the lack of reference information.
Removing Unnecessary Columns and Rows:
Step 1: I identified records with no data in the total_laid_off and percentage_laid_off columns. Since these records are unclear or potentially irrelevant, they were removed.
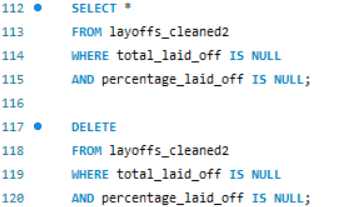
Step2: I dropped the row_num column, as it was a residual column used during duplicate identification and is no longer needed.

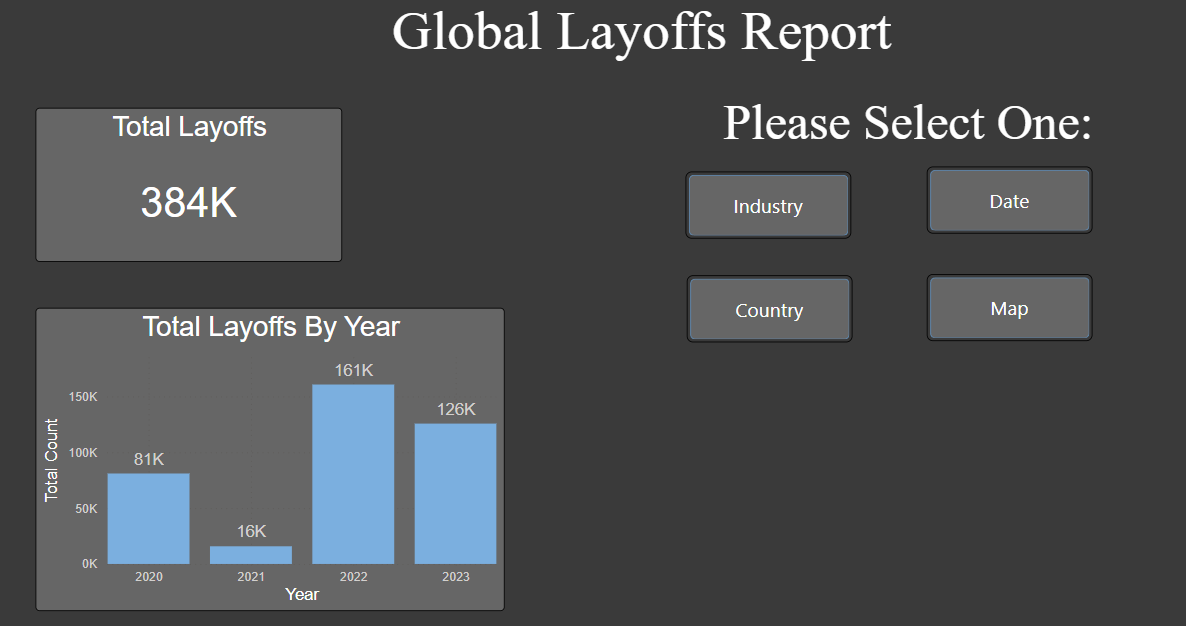
The data is now ready for import into Power BI for visualization and analysis.
Power BI Dashboard: